Predicting and interpreting cell-type-specific drug responses in the small-data regime using inductive priors Reem Alsulami, Robert Lehmann, Sumeer A. Khan, Vincenzo Lagani, Alberto Maillo, David Gomez-Cabrero, Narsis A. Kiani & Jesper Tegner Nature Machine Intelligence (2026). DOI: 10.1038/s42256-026-01202-2
연구 배경
신약 개발은 비용 상승과 생산성 저하라는 이중 과제에 직면해 있다. AI는 de novo 약물 설계, 약물 재창출(repurposing), 개발 파이프라인 최적화 등에서 큰 잠재력을 보이고 있으며, 그 핵심 단계 중 하나가 화학 물질이 세포에 미치는 전사체 수준의 영향을 예측하는 것이다.
기존 접근법의 한계는 명확하다:
| 접근법 | 한계 |
|---|---|
| High-throughput screening (HTS) | 벌크 RNA-seq 기반, 세포 유형별 반응 무시 |
| 단일세포 실험 | 비용이 높고 약물 수가 제한적 (보통 100개 미만) |
| 생성 모델 (scGen, CPA, chemCPA) | 대규모 데이터 필요, 분포 외(OOD) 일반화 어려움 |
단일세포 수준에서 약물의 세포 유형별 전사체 반응을 예측하되, 소규모 데이터에서도 작동하고, 보지 못한 세포 유형이나 약물에도 일반화할 수 있는 방법이 필요하다. 이것이 PrePR-CT의 출발점이다.
핵심 아이디어: 세포 유형별 공발현 네트워크를 귀납적 편향으로 활용
PrePR-CT(Predicting Perturbation Responses in Cell Types)의 핵심 통찰은 단순하면서도 강력하다:
세포 유형마다 고유한 유전자 공발현(co-expression) 패턴이 존재하며, 이것이 약물 반응의 세포 유형 특이성을 결정한다.
이 공발현 패턴을 그래프 구조로 모델링하고, 이를 Graph Attention Network(GAT)의 귀납적 편향(inductive bias)으로 활용함으로써, 학습 데이터에 없던 세포 유형이나 약물에 대해서도 전사체 반응을 예측할 수 있게 된다.
모델 구조
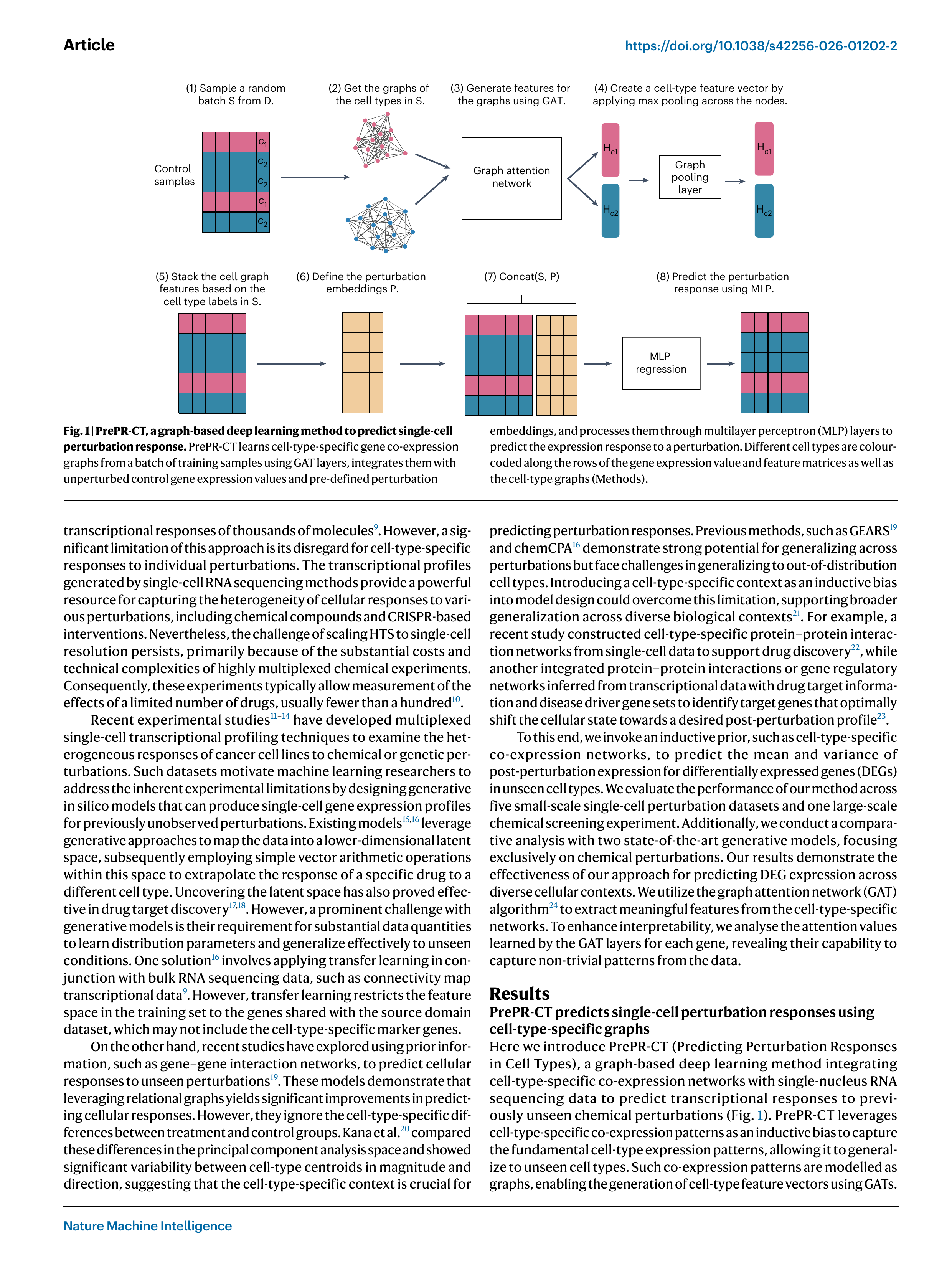 Fig 1. PrePR-CT의 전체 파이프라인. 세포 유형별 공발현 그래프 → GAT → 그래프 풀링 → 약물 임베딩과 결합 → MLP로 전사체 반응 예측
Fig 1. PrePR-CT의 전체 파이프라인. 세포 유형별 공발현 그래프 → GAT → 그래프 풀링 → 약물 임베딩과 결합 → MLP로 전사체 반응 예측
8단계 파이프라인
- 배치 샘플링: 학습 데이터 D에서 랜덤 배치 S 추출
- 세포 유형 그래프 조회: S에 포함된 세포 유형별 공발현 그래프 $G_{c}$ 가져오기
- GAT 특성 추출: 그래프 어텐션 네트워크로 노드(유전자) 수준의 특성 벡터 생성
- 그래프 풀링: Max pooling으로 세포 유형 수준 특성 벡터 생성
- 특성 스택: 세포 유형 레이블에 따라 특성 벡터 정렬
- 약물 임베딩 생성: SMILES → RDKit 화학 기술자(chemical descriptors) → 고정 길이 벡터
- 결합(Concat): 세포 유형 특성 + 약물 임베딩
- MLP 회귀: 교란 후 유전자 발현의 평균과 분산 동시 예측
세포 유형별 공발현 그래프 구축
- 비교란(control) 세포의 단일세포 발현 데이터에서 5,000개 고변이 유전자(HVG) 선정
- SEACells로 메타셀(metacell) 집합 → 유전자 간 피어슨 상관계수 계산
- 상위 1% 상관관계만 엣지로 유지 → 희소 그래프 생성
- 교란 데이터 없이 구축 가능 → 보지 못한 세포 유형에도 적용 가능
손실 함수: Earth Mover’s Distance (EMD)
일반적인 MSE 대신 Wasserstein 거리(EMD)를 사용한다. MSE는 평균만 최적화하는 반면, EMD는 예측 분포와 실제 분포 간의 최적 수송 비용을 최소화하여 분포 전체를 더 잘 포착한다.
\[\text{Loss} = \frac{1}{T} \sum_{t=1}^{T} \text{EMD}(Y_t, \hat{Y}_t)\]주요 결과
1. 보지 못한 세포 유형에서의 단일 약물 반응 예측
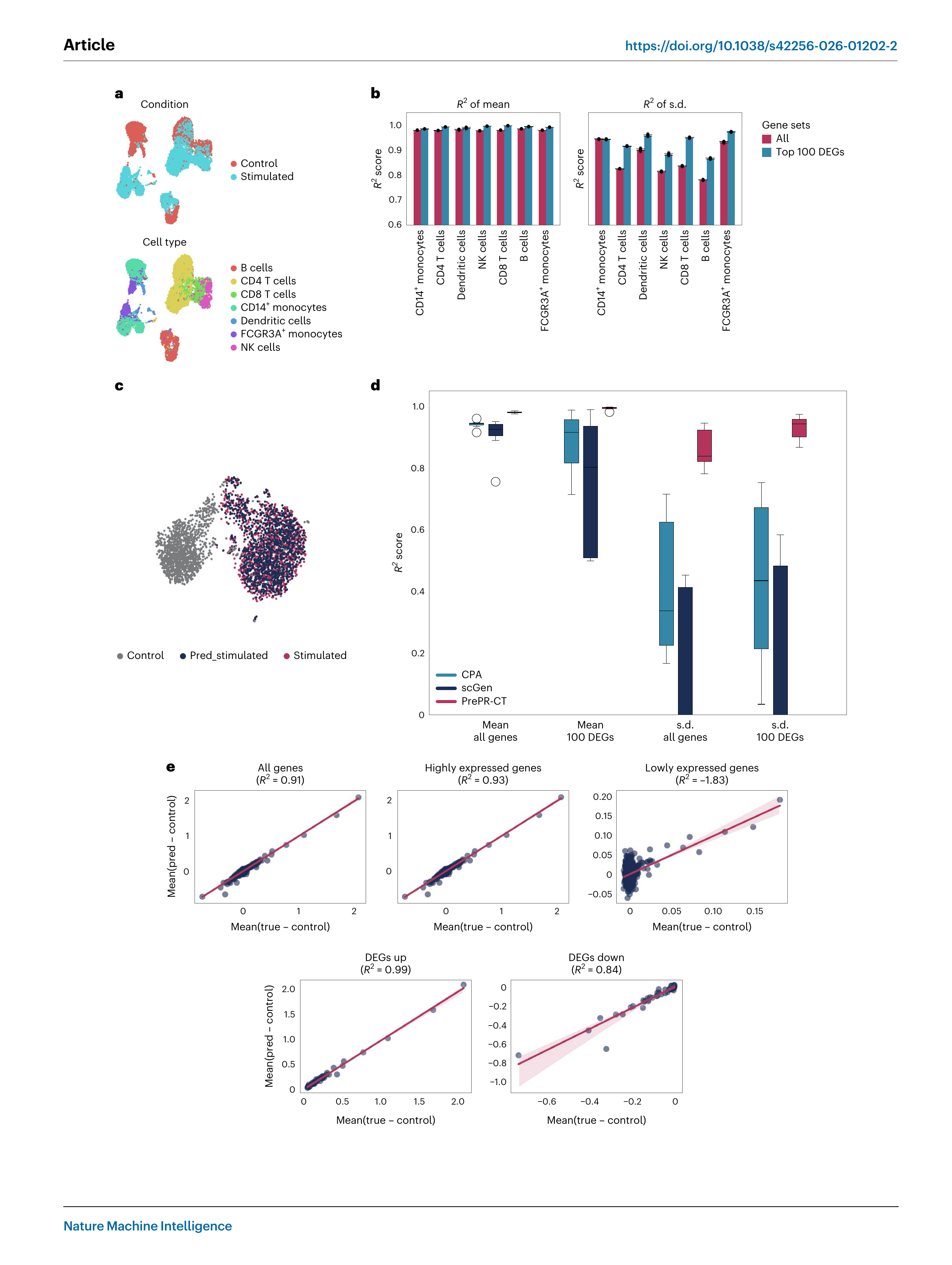 Fig 2. IFNβ 처리에 대한 PBMC 세포 유형별 전사체 반응 예측 (Kang 데이터셋). (a) UMAP, (b) 세포 유형별 R² 점수, (c) B세포 예측 vs 실측 UMAP, (d) CPA·scGen·PrePR-CT 비교, (e) 유전자 발현 수준별 예측 정확도
Fig 2. IFNβ 처리에 대한 PBMC 세포 유형별 전사체 반응 예측 (Kang 데이터셋). (a) UMAP, (b) 세포 유형별 R² 점수, (c) B세포 예측 vs 실측 UMAP, (d) CPA·scGen·PrePR-CT 비교, (e) 유전자 발현 수준별 예측 정확도
Kang 데이터셋(24,249 PBMC 세포, IFNβ 단일 처리)에서 leave-one-cell-type-out 교차검증을 수행했다.
| 지표 | PrePR-CT | CPA | scGen |
|---|---|---|---|
| 평균 발현 R² (전체 유전자) | > 0.90 | ~0.85 | ~0.80 |
| 평균 발현 R² (상위 100 DEG) | > 0.90 | ~0.90 | ~0.85 |
| 발현 분산 R² (전체 유전자) | > 0.70 | ~0.40 | ~0.30 |
| 세포 유형 간 R² 변동성 | 가장 낮음 | 중간 | 높음 |
유전자를 발현 수준별로 분류했을 때:
- 고발현 유전자: R² = 0.93
- 상향 조절 DEG: R² = 0.99
- 하향 조절 DEG: R² = 0.84
- 저발현 유전자: R² = -1.83 (거의 변화 없는 유전자, 예측 무의미)
PrePR-CT는 실제 전사체 변화가 있는 유전자에서 매우 정확하며, 변화가 거의 없는 유전자에서는 노이즈에 과적합하지 않는 바람직한 특성을 보였다.
2. 다중 약물 반응 예측 (NeurIPS PBMC 데이터셋)
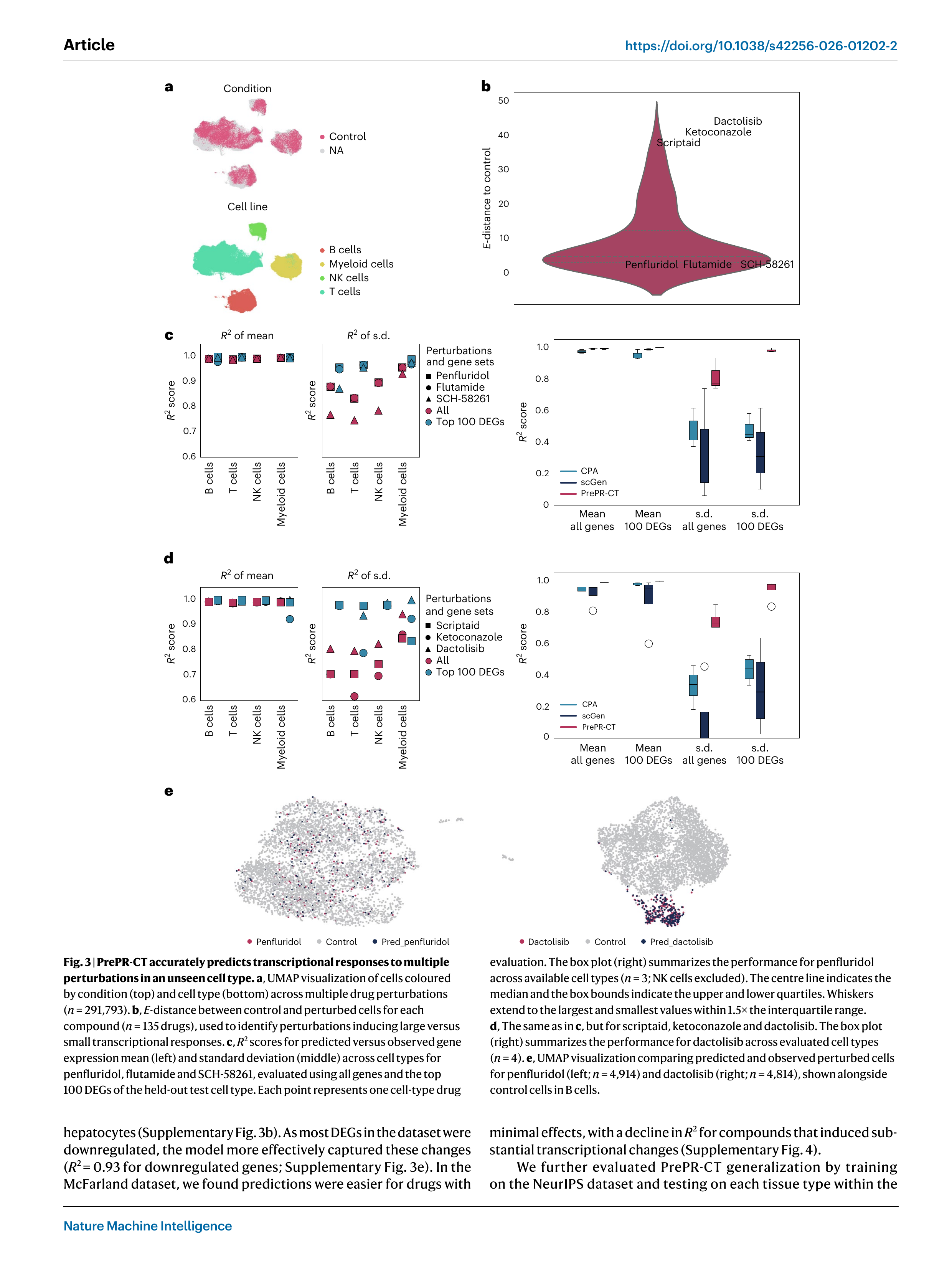 Fig 3. NeurIPS PBMC 데이터셋에서 144개 약물 × 4개 면역세포 유형에 대한 예측 성능. (a) UMAP, (b) 약물별 전사체 변화 강도, (c-d) 약한/강한 교란 약물의 성능 비교, (e) 예측 세포와 실측 세포의 UMAP 비교
Fig 3. NeurIPS PBMC 데이터셋에서 144개 약물 × 4개 면역세포 유형에 대한 예측 성능. (a) UMAP, (b) 약물별 전사체 변화 강도, (c-d) 약한/강한 교란 약물의 성능 비교, (e) 예측 세포와 실측 세포의 UMAP 비교
144개 소분자 약물 × 4개 면역세포 유형(B세포, T세포, NK세포, 골수세포)을 포함하는 대규모 데이터셋에서의 결과:
- 전사체 변화가 약한 약물(penflurido, flutamide 등): 높은 예측 정확도
- 전사체 변화가 강한 약물(dactolisib, ketoconazole 등): 예측이 더 어렵지만, PrePR-CT가 발현 분산 예측에서 일관되게 우수
- UMAP 시각화에서 예측 세포가 실측 교란 세포와 정확히 겹침 (penflurido의 경우)
3. 보지 못한 약물에 대한 일반화 (Chang 데이터셋)
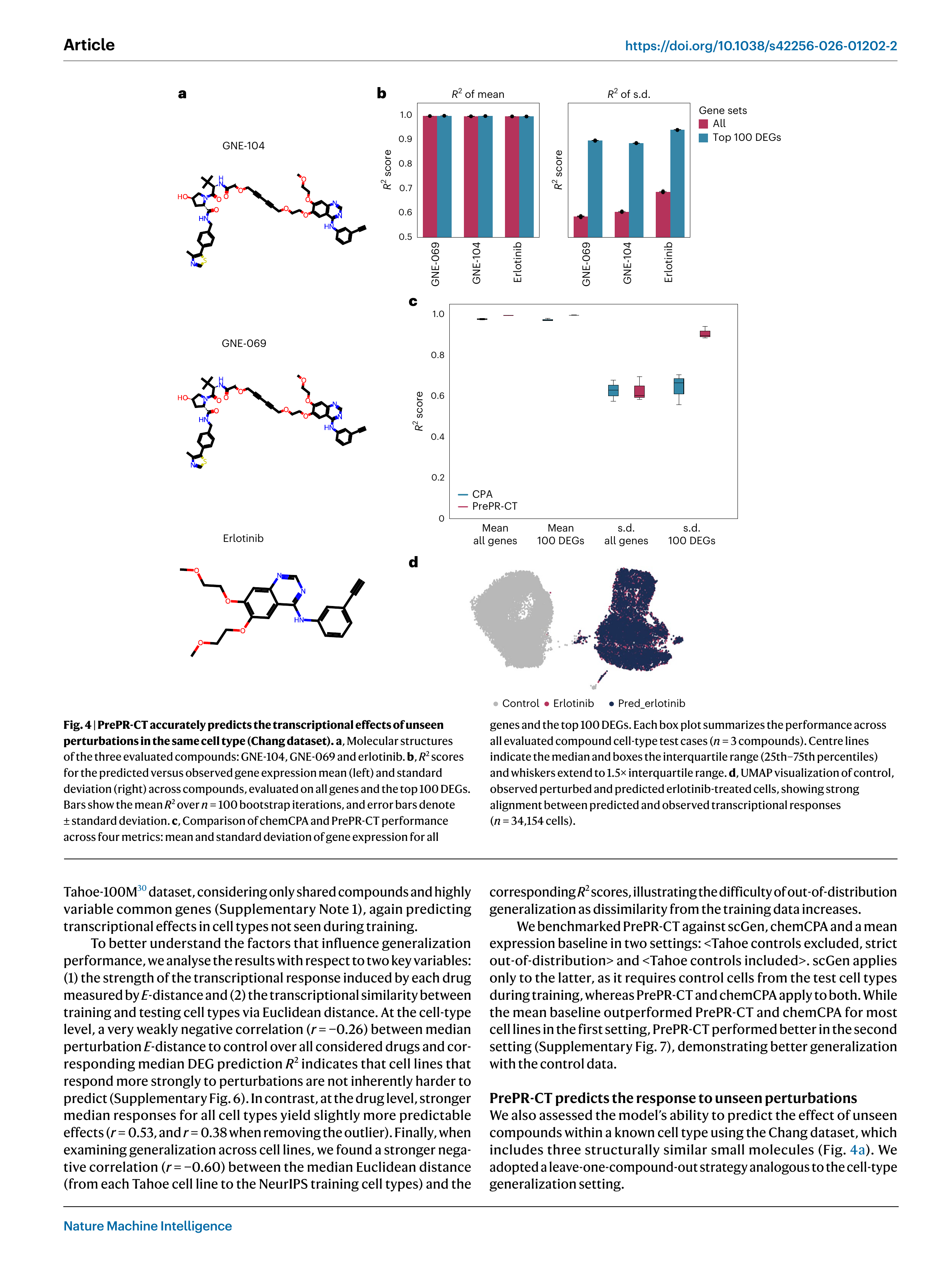 Fig 4. 구조적으로 유사한 3개 화합물(GNE-104, GNE-069, erlotinib) 간 leave-one-compound-out 교차검증. (a) 분자 구조, (b) R² 점수, (c) chemCPA와 비교, (d) erlotinib UMAP 시각화
Fig 4. 구조적으로 유사한 3개 화합물(GNE-104, GNE-069, erlotinib) 간 leave-one-compound-out 교차검증. (a) 분자 구조, (b) R² 점수, (c) chemCPA와 비교, (d) erlotinib UMAP 시각화
구조적으로 유사한 3개 EGFR 억제제에 대해 leave-one-compound-out 검증을 수행했다:
- 평균 발현 예측: 모든 약물에서 R² > 0.85
- 특히 erlotinib에서 발현 분산 R²가 현저히 높음
- chemCPA 대비 발현 분산 예측에서 유의하게 우수
- UMAP에서 예측 erlotinib 처리 세포가 실측과 강하게 겹침
4. 소규모 데이터에서의 강건성
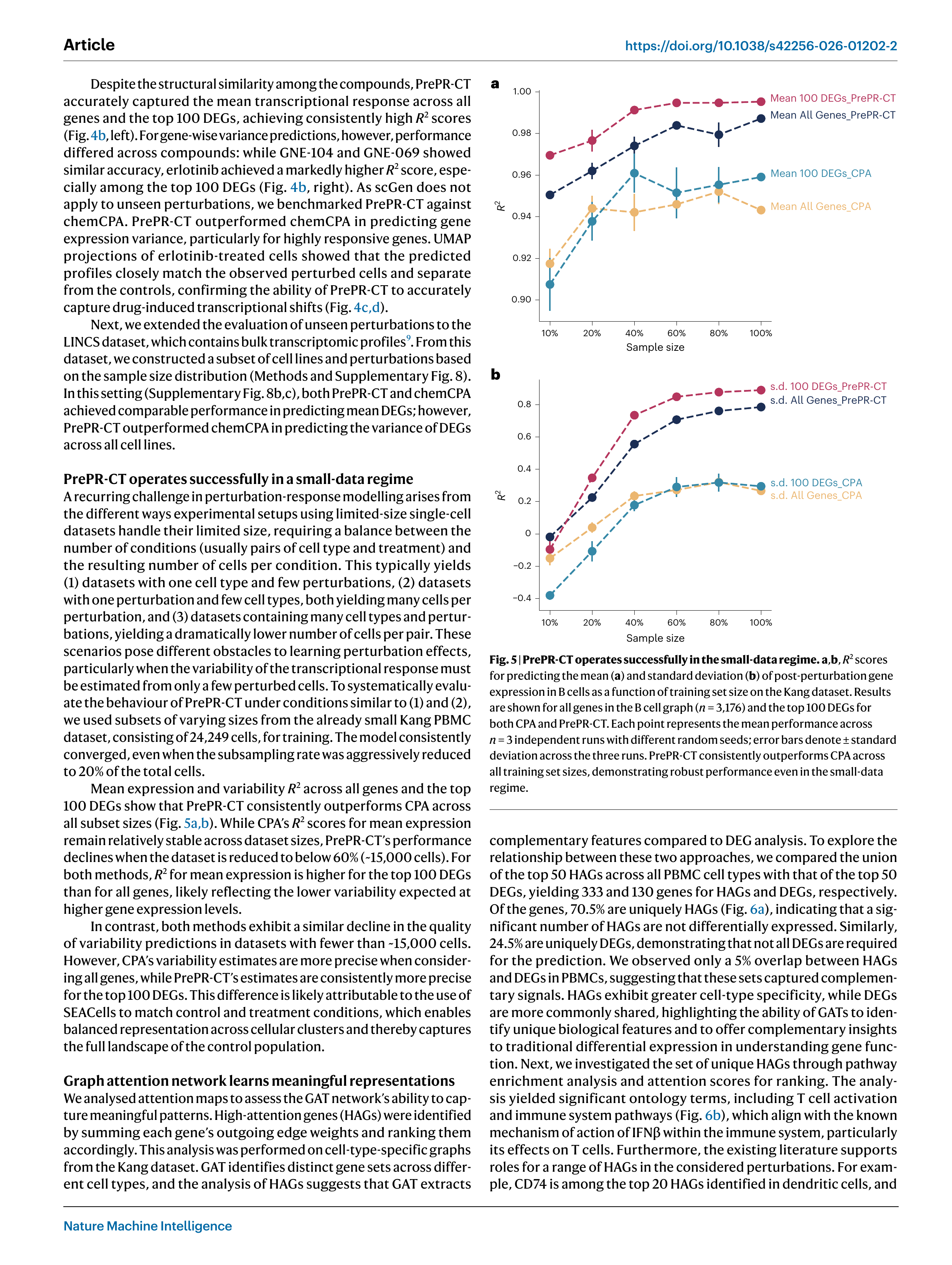 Fig 5. 학습 데이터 크기에 따른 성능 변화. (a) 평균 발현 R², (b) 표준편차 R². 데이터의 20%만으로도 수렴
Fig 5. 학습 데이터 크기에 따른 성능 변화. (a) 평균 발현 R², (b) 표준편차 R². 데이터의 20%만으로도 수렴
이 결과가 PrePR-CT의 가장 큰 실용적 장점이다:
- 전체 데이터의 20%만으로도 성능 수렴 (~15,000 세포 → ~3,000 세포)
- 평균 발현 R²: CPA는 60% 이하에서 급격히 하락하지만, PrePR-CT는 안정적
- 발현 분산 R²: CPA는 ~15,000 세포 이하에서 음수(예측 불가), PrePR-CT는 양수 유지
이는 공발현 네트워크라는 귀납적 편향이 데이터 부족을 효과적으로 보상한다는 것을 의미한다. 단일세포 약물 스크린 실험은 비용이 높고 세포 수가 제한적이기 때문에, 이 특성은 실제 적용에서 매우 중요하다.
5. GAT가 학습하는 생물학적 의미: High-Attention Genes (HAGs)
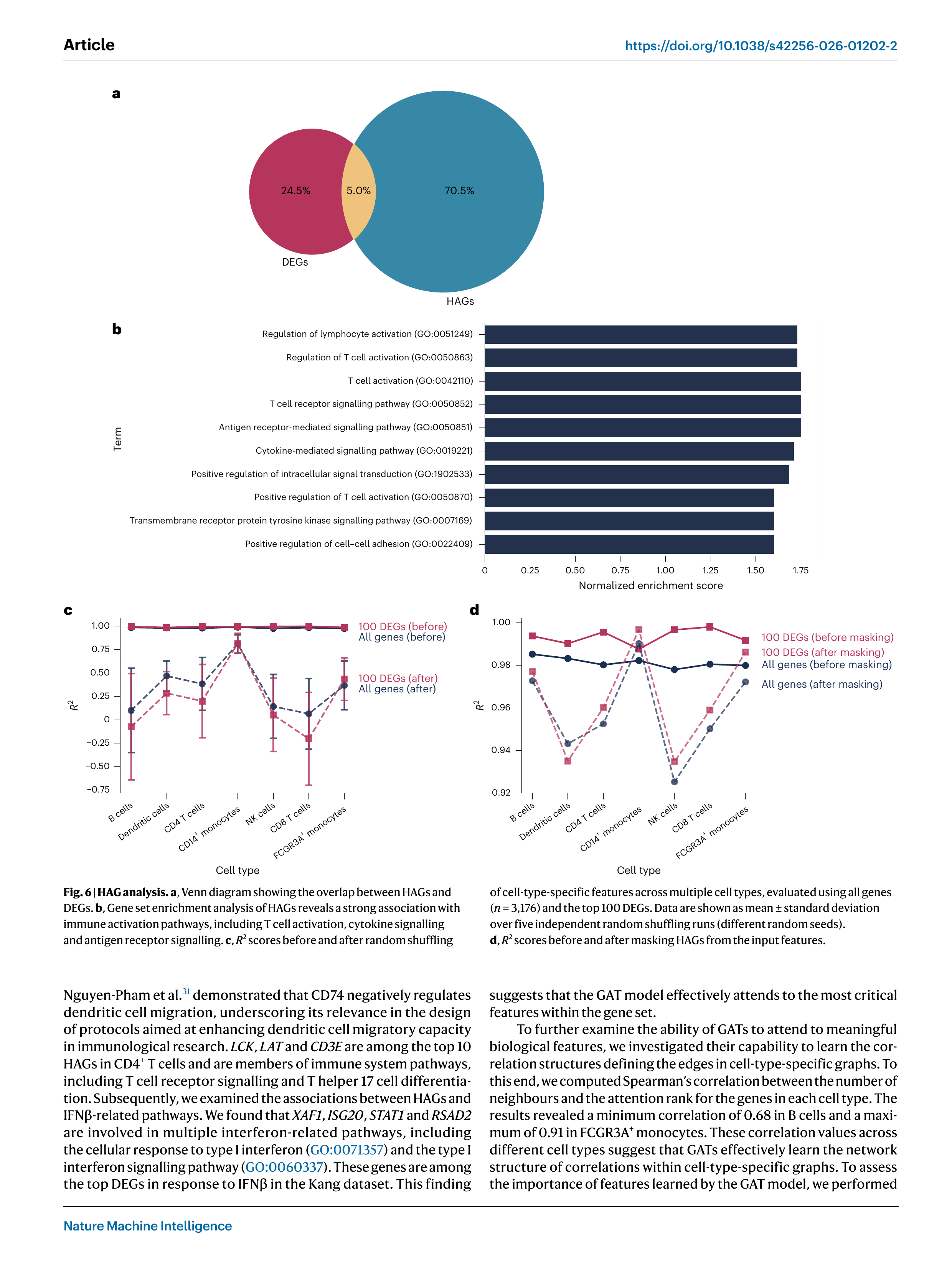 Fig 6. GAT 어텐션 분석. (a) HAG와 DEG의 벤 다이어그램 — 5%만 겹침, (b) HAG 유전자의 GO 경로 분석, (c-d) 특성 셔플링 및 마스킹 절제 실험
Fig 6. GAT 어텐션 분석. (a) HAG와 DEG의 벤 다이어그램 — 5%만 겹침, (b) HAG 유전자의 GO 경로 분석, (c-d) 특성 셔플링 및 마스킹 절제 실험
GAT의 어텐션 가중치를 분석하여 High-Attention Genes (HAGs) — 모델이 가장 주목하는 유전자들을 식별했다.
HAGs vs DEGs: 상보적 관계
| 비교 | 비율 |
|---|---|
| HAGs 고유 | 70.5% |
| DEGs 고유 | 24.5% |
| 공통 | 5.0% |
HAGs와 DEGs는 95%가 겹치지 않는다. 이는 GAT가 단순히 차등 발현 유전자를 학습하는 것이 아니라, 교란 반응을 예측하는 데 필요한 세포 유형 맥락 정보를 담은 유전자를 학습한다는 것을 의미한다.
HAGs의 경로 분석
HAGs의 GO 경로 분석 결과, T세포 활성화, 사이토카인 신호전달, 항원 수용체 신호전달 등 IFNβ의 알려진 작용 메커니즘과 일치하는 면역 경로가 풍부하게 나타났다.
대표적 HAGs:
- CD74: 수지상세포 이동을 음성 조절 — 면역학 연구에서 잘 알려진 표적
- LCK, LAT, CD3E: CD4⁺ T세포의 T세포 수용체 신호전달 핵심 유전자
- XAF1, ISG20, STAT1, RSAD2: IFNβ 관련 인터페론 신호전달 경로 유전자
절제 실험 (Ablation Study)
- 특성 셔플링 (세포 유형 특이성 제거): 상위 100 DEG R²가 크게 하락 → 세포 유형 맥락이 핵심
- HAG 마스킹 (어텐션 높은 유전자 제거): R² 하락 관찰 → HAGs가 예측에 직접 기여
- DEGs가 셔플링에 더 민감하고, HAGs가 마스킹에 더 민감 → 상보적 역할 확인
방법론적 특장점 요약
| 특성 | PrePR-CT | scGen | CPA/chemCPA |
|---|---|---|---|
| 세포 유형 맥락 | 공발현 그래프 | 없음 | 잠재 공간 연산 |
| 보지 못한 세포 유형 | 가능 | 제한적 | 제한적 |
| 보지 못한 약물 | 가능 | 불가능 | 가능 |
| 소규모 데이터 | 강건 | 약함 | 약함 |
| 해석 가능성 | GAT 어텐션 | 없음 | 잠재 공간 |
| 손실 함수 | EMD | MSE | MSE |
| 화학 구조 정보 | SMILES 임베딩 | 없음 | SMILES |
한계점
저자들이 명시한 한계와 추가적인 고려사항:
- 그래프 노드 특성의 제한: 현재 유전자 발현의 평균과 분산만 사용. 세포 주기 상태, 형태학적 특성, 조직 기원 등을 통합하면 성능 향상 가능
- 분포 외 일반화의 어려움: NeurIPS → Tahoe 데이터셋 간 전이에서 전사체 거리가 멀수록 성능 저하
- HAG의 불안정성: 어텐션 헤드 수 등 하이퍼파라미터에 민감하여, DEG 분석보다 재현성이 낮음
- 배치 효과: 실험 간 프로토콜 차이, 배치 효과가 참 효과를 가릴 수 있음
개인 소감
이 논문이 제시하는 “세포 유형별 공발현 네트워크를 귀납적 편향으로 사용한다”는 아이디어는 우아하고 실용적이다. 특히 세 가지 측면에서 인상적이었다.
첫째, 소규모 데이터에서의 강건성이다. 단일세포 약물 스크린은 여전히 비싸고 데이터가 제한적인 상황에서, 데이터의 20%만으로도 성능이 수렴한다는 것은 실제 약물 발견 파이프라인에서의 적용 가능성을 크게 높인다.
둘째, HAGs와 DEGs의 상보성 발견이다. 모델이 학습하는 유전자(HAGs)의 95%가 전통적 차등 발현 분석(DEGs)과 겹치지 않는다는 것은, GAT가 단순히 결과를 예측하는 것이 아니라 약물 반응의 세포 유형 맥락이라는 새로운 생물학적 층위를 포착하고 있음을 시사한다.
셋째, EMD 손실 함수의 선택이다. 단일세포 데이터의 본질은 분포이지 평균이 아니다. MSE에서 EMD로의 전환은 작은 변화처럼 보이지만, 세포 집단 내 이질성(heterogeneity)을 보존하는 데 결정적이다.
향후 이 접근법이 약물 조합 효과 예측, 치료 표적 식별, 그리고 환자 유래 단일세포 데이터와의 통합으로 확장된다면, 정밀 의학에서의 약물 반응 예측에 실질적으로 기여할 수 있을 것이다.
References
- Alsulami, R., Lehmann, R., Khan, S. A., Lagani, V., Maillo, A., Gomez-Cabrero, D., Kiani, N. A. & Tegner, J. (2026). Predicting and interpreting cell-type-specific drug responses in the small-data regime using inductive priors. Nature Machine Intelligence. DOI: 10.1038/s42256-026-01202-2
💬 댓글